Ever wondered if your carefully crafted machine learning model is truly learning or just cleverly mimicking? Model evaluation isn't merely a post-training ritual; it's the bedrock upon which reliable AI systems are built. It ensures that these systems, increasingly integral to our lives, function as intended and deliver trustworthy results.
Think of it like this: training a model is akin to teaching a student a complex subject. You provide them with information, examples, and exercises. But how do you know if they've genuinely grasped the core concepts or simply memorized the answers? That's where model evaluation comes in. It's the equivalent of giving the student a comprehensive exam, designed to test their understanding and ability to apply their knowledge in new and challenging situations. Without rigorous evaluation, we risk deploying models that appear proficient on the surface but fail spectacularly when faced with real-world data.
| Category | Details |
|---|---|
| Definition | Model evaluation is a process that uses metrics to analyze a model's performance. |
| Analogy | Similar to testing a student to see if they truly learned the subject matter. |
| Importance | Crucial for determining the effectiveness and reliability of machine learning models. |
| Measurement | Requires quantitative measurement with reference to ground truth output (evaluation metrics). |
| Challenge | Model evaluation in LLM applications is complex and lacks a unified approach. |
| Techniques | Involves using various metrics for classification, regression, and clustering. |
| Metrics | Area under the ROC curve (AUC) is a possible evaluation metric with values in [0, 1]. |
| Application | Evaluation metrics are used in classification problems, regression problems, and clustering. |
| Ground Truth | Supervised evaluation uses ground truth class values for each sample. |
| Quality | Unsupervised evaluation measures the quality of the model itself. |
| Selection | Choosing appropriate evaluation metrics is essential. |
| Dependency | The choice of metric depends on the problem at hand and the nature of the data. |
| Generative AI | Assessing generative AI model performance requires quantitative and qualitative evaluation. |
| Regression | Regression metrics are quantitative measures used to evaluate regression models. |
| Classification | Binary classifiers use rank view, thresholding metrics, and confusion matrix point metrics. |
| Quantification | Evaluation metrics quantify and aggregate the quality of the trained classifier. |
| Validation | Used to validate the classifier with unseen data. |
| Refinement | Evaluation metrics determine if further refinement is required. |
| Large Language Models (LLMs) | Metrics are essential for evaluating LLMs. |
| Common Metrics | Common metrics include MSE, RMSE, MAE, and MAPE. |
| Access | Evaluation metrics access the performance of machine learning models. |
| TensorFlow | In TensorFlow, metrics help quantify model performance during and after training. |
In the realm of machine learning, particularly with the rise of sophisticated Large Language Models (LLMs), model evaluation emerges as a critical cornerstone. It's the compass that guides us in navigating the complex landscape of algorithms, ensuring that our creations are not only intelligent but also reliable and trustworthy. As LLM applications rapidly evolve, the need for robust evaluation methods becomes even more pronounced. However, the challenge lies in the fact that there isn't a universally accepted approach to measuring their effectiveness. This necessitates a deeper understanding of the available evaluation metrics and their appropriate application across various tasks.
- Super 30 Vegamovies What Went Wrong Find Alternatives
- Bolly4u Your Guide To Free Bollywood Movie Streaming
At its core, model evaluation is a systematic process that leverages a range of metrics to dissect and analyze a model's performance. These metrics act as quantitative yardsticks, providing concrete data on how well the model is achieving its intended goals. To truly understand the model's capabilities, these measurements must be taken with reference to "ground truth" output the actual, correct answers. This comparison forms the basis for determining the model's accuracy, precision, and overall effectiveness. Without this quantitative rigor, we risk relying on subjective impressions, which can be misleading and ultimately detrimental.
One of the fundamental challenges in model evaluation stems from the diverse nature of machine learning tasks. From classification to regression and clustering, each task requires a specific set of evaluation metrics that are tailored to its unique characteristics. For instance, in classification problems, we might employ metrics like accuracy, precision, recall, and F1-score to assess how well the model is able to categorize data points into predefined classes. In regression problems, on the other hand, we might use metrics like Mean Squared Error (MSE), Root Mean Squared Error (RMSE), or Mean Absolute Error (MAE) to measure the difference between the model's predictions and the actual values. And in clustering, we might use metrics like Silhouette score or Davies-Bouldin index to evaluate the quality of the clusters formed by the model.
To further illustrate the importance of evaluation metrics, let's consider the Area Under the ROC Curve (AUC). The AUC provides a comprehensive measure of a model's ability to discriminate between different classes, ranging from 0 to 1. Unlike some other metrics, the AUC is independent of the specific threshold chosen for classification. This makes it particularly useful when dealing with imbalanced datasets, where one class has significantly more samples than the other. However, it's crucial to remember that the AUC is just one piece of the puzzle. It should be used in conjunction with other evaluation metrics to gain a holistic understanding of the model's performance.
- Filmyfly Your Hub For Bollywood Hollywood More Watch Now
- Fry99com Is It Safe What You Need To Know 2024 Update
Delving deeper into the world of evaluation metrics, we encounter a distinction between supervised and unsupervised evaluation. Supervised evaluation relies on "ground truth" class values for each sample, allowing us to directly compare the model's predictions to the known correct answers. This approach is commonly used in classification and regression tasks. Unsupervised evaluation, conversely, operates without the benefit of ground truth. Instead, it focuses on measuring the "quality" of the model itself, assessing aspects like cluster cohesion and separation. This type of evaluation is typically used in clustering and dimensionality reduction tasks.
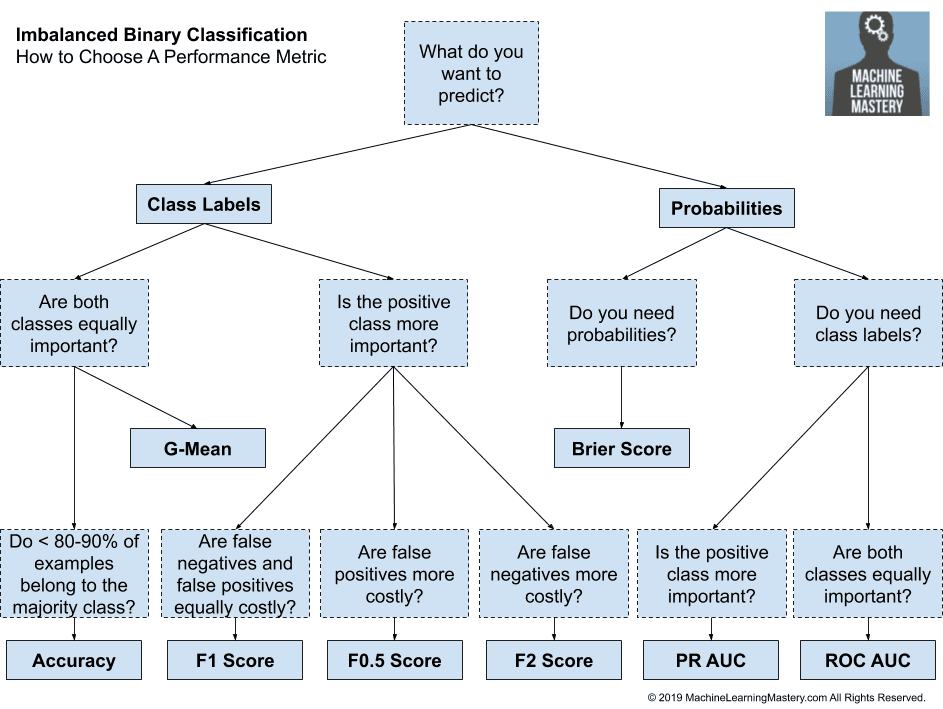
The choice of appropriate evaluation metrics is paramount. A poorly chosen metric can lead to a misrepresentation of the model's capabilities and, ultimately, to flawed decision-making. The selection process must take into account the specific problem at hand, the nature of the data, and the desired outcome. For example, if the goal is to minimize false positives (incorrectly identifying a negative case as positive), then precision would be a more relevant metric than recall. On the other hand, if the goal is to minimize false negatives (incorrectly identifying a positive case as negative), then recall would be more important than precision.
Moreover, the assessment of Generative AI models introduces unique challenges. Unlike traditional machine learning models that focus on prediction or classification, Generative AI models aim to create new data that resembles the training data. Evaluating their performance requires a combination of quantitative and qualitative measures. Quantitative measures might include metrics like Perplexity or Inception Score, which assess the quality and diversity of the generated samples. Qualitative measures, on the other hand, involve human evaluation, where experts assess the generated samples for realism, coherence, and overall quality.
In the realm of regression models, several key metrics come into play. Mean Squared Error (MSE) calculates the average squared difference between the predicted and actual values. Root Mean Squared Error (RMSE) is simply the square root of the MSE, providing a more interpretable measure in the original units of the data. Mean Absolute Error (MAE) calculates the average absolute difference between the predicted and actual values, offering a more robust measure to outliers than MSE or RMSE. And finally, Mean Absolute Percentage Error (MAPE) calculates the average percentage difference between the predicted and actual values, providing a scale-independent measure of error.
For binary classifiers, a variety of evaluation metrics are available, each offering a unique perspective on the model's performance. These include rank view metrics, thresholding metrics, and confusion matrix point metrics. Rank view metrics assess the model's ability to rank data points according to their likelihood of belonging to a particular class. Thresholding metrics evaluate the model's performance at different classification thresholds. And confusion matrix point metrics provide a detailed breakdown of the model's predictions, highlighting the number of true positives, true negatives, false positives, and false negatives.
Ultimately, the evaluation metric serves as a crucial tool for quantifying and aggregating the quality of a trained classifier, especially when validated with unseen data. The results of these evaluation metrics determine whether the classifier has performed optimally or whether further refinement is required. This iterative process of evaluation and refinement is essential for building robust and reliable machine learning models.
In the context of Large Language Models (LLMs), metrics are an indispensable element in evaluating any AI system. They provide a means to assess the model's ability to perform various language tasks, such as text generation, translation, and question answering. Several popular metrics are used to evaluate LLMs, including BLEU, ROUGE, and METEOR. These metrics compare the generated text to a reference text, measuring aspects like n-gram overlap, precision, and recall.
In TensorFlow, evaluation metrics play a vital role in quantifying how well the model is performing both during training and after it has been trained. TensorFlow provides a rich set of built-in metrics that can be easily integrated into the training loop. These metrics provide valuable insights into the model's progress, allowing developers to fine-tune the model and optimize its performance.
In closing, the journey through model evaluation highlights its multifaceted nature and its critical importance in the development of reliable and effective machine learning systems. From understanding the nuances of various evaluation metrics to appreciating the specific challenges posed by different types of models, a thorough understanding of model evaluation is essential for any data scientist or machine learning engineer.
- Movierulz 2025 Latest Movie News Risks Legal Options Explored
- Adultmovierulz Explore The Hottest Adult Movies More